使用CUDA的PyTorch进行张量重整化的gpu加速
- 摘要
- Introduction
- Algorithm and TorchTrg discussion
- Models and Results
GPU-Acceleration of Tensor Renormalization with PyTorch using CUDA
摘要
作者展示了基于张量重整化群(TRG)方法的数值计算可以通过利用NVIDIA的计算统一设备架构(CUDA)在图形处理单元(GPU)上的PyTorch显著加速。作者发现,在二维系统中,对于给定的精度,运行时间以及与边界维度的扩展都得到了改进。作者的结果表明,在未来的高精度TRG计算中,利用GPU资源是至关重要的。
Introduction
研究低维经典/量子自旋系统的最先进传统方法无疑是张量网络法。这一方法始于人们认识到,一维局域哈密顿系统的基态可以有效地用矩阵乘积态(MPS)来表示,然后可以通过已知的算法进行优化。这个想法及其一些高维推广现在被常规用于模拟低纠缠量子系统[1]。有一种替代方法[2, 3],它更符合基于拉格朗日量或配分函数的格点场理论,称为张量重整化群(TRG)。这使得作者能够通过阻塞张量网络来进行精确重整化群方程的数值近似版本,以计算欧几里得配分函数。如果这种阻塞(粗粒化)递归应用,就会生成在更大长度尺度上的理论描述,并伴随着有效耦合的相应流动。除了将TRG应用于离散自旋模型(首次引入的地方)之外,它还用于研究具有连续对称性和二维及更高维度中的规范理论[4, 5, 6, 7]。对于有兴趣的读者,作者推荐综述文章[8]以开始参考文献的追踪。
作为一种替代标准蒙特卡罗基格点规范计算的高精度TRG计算前景,有几个动机。最重要的是,它能够研究在有限化学势或拓扑项存在下的复作用系统。由于TRG算法不使用采样技术,因此它们不会受到符号问题[5, 9, 10]的困扰。然而,权衡似乎是这样的:TRG计算的截断(无法避免)并不总是能产生底层连续场理论的正确行为。
计算时间的大部分是在连续迭代过程中张量的收缩。如果能够有效地进行这一操作,将带来实质性的改进,这对于研究高维系统至关重要。使用ATRG[11]和HOTRG[3]在四维探索中利用了并行CPU计算来加速计算,并取得了良好的结果[12]。
张量的不合理有效性并不仅限于定义物理系统。在机器学习应用中,张量被广泛用于存储高维经典数据和训练模型。由于这个领域有广泛的含义,已经开发出了一些端到端的软件包,现在可以使用各种可扩展的软件包,如TensorFlow和PyTorch,它们也可用于物理计算。PyTorch[13]是一个Python包,提供了一些高级功能,如带有强大GPU加速的张量收缩和建立在反向模式自动微分系统上的深度神经网络,这是反向传播(机器学习算法的一个关键要素)中的一个重要步骤。尽管有一些使用CUDA(一个允许程序员使用NVIDIA GPU进行通用计算的并行计算平台)[14]的MPS张量网络实现的探索,但据作者所知,它在实空间TRG社区并没有被广泛认可或探索。CUDA提供了如cuBLAS和cuDNN等库,可以利用张量核心和专业硬件单元快速进行张量收缩。
在本文中,作者展示了使用PyTorch和CUDA以及opt_einsum[15]对代码进行简单修改,可以使广义XY模型(在第3节中描述)的运行时间提高约x,当时。作者还为有兴趣的读者提供了伊辛模型和3态波茨模型的结果,以及如何用较少的计算机时间获得最先进的结果。作者将使用PyTorch和CUDA进行TRG计算的方法称为TorchTrg,本文中使用的代码可以从参考文献[16]获得。
Algorithm and TorchTrg discussion
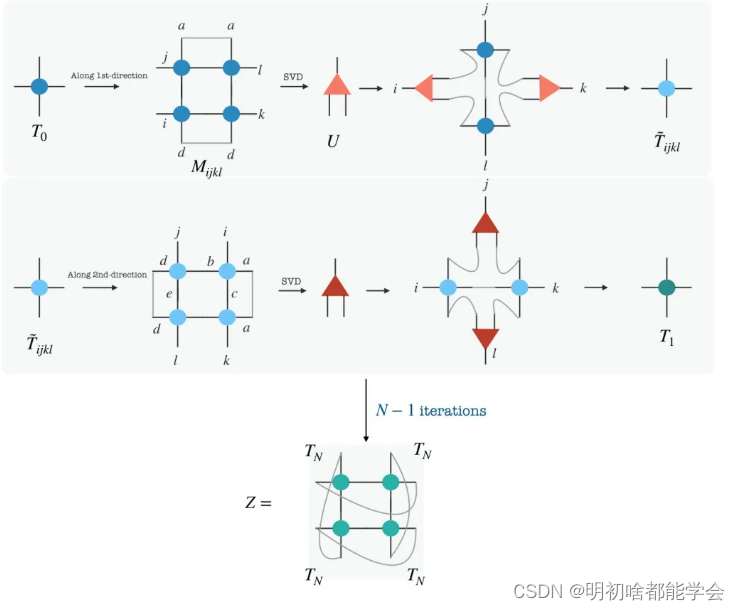
作者使用了基于张量的高阶奇异值分解(HOSVD)的高阶TRG算法。在过去的十年里,这一算法已经被彻底研究,具体细节请参阅最近的综述文章[8]。该算法的目标是通过指定一个局部的边界维度D,在整个算法过程中保持其恒定,有效地执行具有受控截断的张量网络的粗粒化。作者在图2中展示了一个使用高阶TRG算法的完整粗粒化迭代过程。
第一步是将四个初始张量(表示为
T
T
T)组合起来构建
M
i
j
k
l
M_{ijkl}
Mijkl。然后作者将左右索引组合起来构建一个矩阵,并对该矩阵进行奇异值分解(SVD)以获得投影仪
U
U
U。接着作者沿着特定方向组合张量以获得粗粒化张量
T
T
T。然后作者使用这个张量,沿着正交方向执行类似的步骤以获得
T
T
T。这构成了一个粗粒化步骤。再执行
N
−
1
N-1
N−1次这样的步骤,然后用周期边界条件收缩指标,作者得到了
Z
Z
Z的近似值。作者在图1中为读者展示了算法。对于
d
d
d维欧几里得系统,高阶TRG算法的计算复杂度按
O
(
D
4
d
−
1
)
O(D^4d-1)
O(D4d−1)的比例增长。HOTRG计算(尤其是对于高维)最昂贵的部分是与固定截断
D
D
D的张量收缩。这需要将增长的大小根据资源保持在一个合理值。张量收缩与SVD之间的时间复杂度比是
O
(
D
4
d
−
7
)
O(D^4d-7)
O(D4d−7)。在作者之一之前的工作[17]中,为了执行张量收缩,使用了mcon Python库。有一种在机器学习中被广泛使用并已知为opt_einsum[18]的等效方法来进行这些收缩,该方法在[19]中用于标准CPU计算。在这项工作中,作者通过在没有明确将任何张量复制到GPU设备的情况下在GPU架构上执行这些收缩,利用了opt_einsum的附加功能。为此,需要一个更高性能的后端,该后端需要来回转换数组类型。opt_einsum软件可以自动处理这些转换,支持一系列选项,如TensorFlow、Theano、jax和PyTorch。在这项工作中,作者在NVIDIA GeForce RTX 2080 Ti上使用PyTorch。将主要针对机器学习的软件包(如PyTorch和TensorFlow)用于多体物理问题并不是新事物。TensorFlow被用于研究使用基于[21]中开发的软件包的树状张量网络的自旋链。[20]然而,作者尚未了解到任何实空间张量重整化群算法利用这些基于ML/AI的Python软件包的GPU加速并进行了显示改进的系统性研究。使用PyTorch的另一个优点是能够使用torch_tensor(T, requires_grad=True)进行自动微分,这在计算类似于[22]中的导数时很有用。另外,可用GPU的增加也极大地加速了程序,作者将在下一节中讨论这一点。下面总结了涉及转换到所需后端(如果可用CUDA)并执行粗粒化步骤的主要步骤:
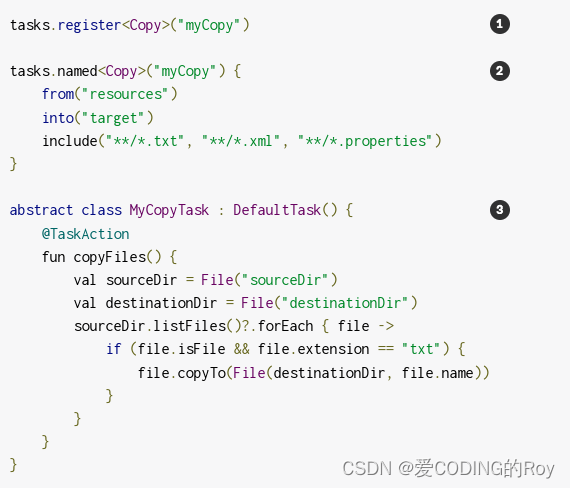
- 首先,将所有张量初始化为 torch CPU 张量。
- 对于张量收缩,作者使用了库 opt_einsum_torch,它利用 GPU 核心进行收缩并返回一个 torch CPU 张量[15]。
- 作者使用了 torch._linalg 内置的线性代数库来执行奇异值分解 (SVD) 和其他基本操作。
图 1: 展示了本文中实现的高阶TRG的示意图。从上至下,从左至右观看,前两个面板表示沿着两个方向的粗粒化。第一步是将四个初始张量 (表示为 T 0 T_0 T0) 组合起来构造 M i j k l M_{ijkl} Mijkl。然后作者将左右索引组合起来构造一个矩阵,并对该矩阵进行奇异值分解以获得投影仪 U U U。接着作者沿着特定方向组合张量以获得粗粒化张量 T T T。然后使用这个张量,作者在正交方向上执行类似的步骤以获得 T T T。这构成了一个粗粒化步骤。再将这个过程执行 N − 1 N - 1 N−1 次,然后收缩索引,作者得到了周期性边界条件下 Z Z Z 的近似。
在GPU上进行张量收缩可以减少CPU上的内存负载,提高程序的效率。作者观察到随着GPU架构的改进,计算成本进一步降低。作者选择使用 opt_einsum,因为它可以通过优化最佳的可能时间复杂度顺序,将许多操作调度到标准的 BLAS 或 cuBLAS (提供 GPU 加速的 BLAS 实现) [18, 23],从而显著减少张量网络收缩的总体执行时间。在任何量子多体计算中,张量收缩的顺序都是一个重要的考虑因素。作者在附录A中重新讨论了这个问题,并展示了它们在计算时间上的显著差异。以下是作者为感兴趣的读者提供的一些代码段和解释。
该程序需要三个主要库: numpy、scipy、torch,作者在开始时导入了它们。作者还检查是否可以使用GPU,即是否可以使用CUDA。如果可用,将整个计算中的 use_cuda == True 设置。如果CUDA可用,作者打印设备数量、名称和内存,并引入了爱因斯坦求和(张量收缩)的规划器。请注意,来自文献[15]的规划器实现了一个内存高效的爱因斯坦求和函数,使用PyTorch作为后端,并使用opt_einsum包优化收缩路径以达到最小的FLOPS。如果 use_cuda == False,那么作者只需导入opt_einsum包的基本版本作为 contract。contract 和基于CUDA的 einsum 的表示法相似。为了计算
A
j
,
a
B
p
,
j
,
a
−
C
i
,
p
,
k
,
q
A_{j,a}B_{p,j,a} - C_{i,p,k,q}
Aj,aBp,j,a−Ci,p,k,q,作者执行:
if use_cuda == True:
C = torch.einsum("ja,pja->ipaq", A, B)
else:
C = contract("japja->ipaq", A, B)
有时为了解决一些错误,可以执行以下操作:
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:3"
# 调整 cuda_mem_limit 也有帮助
ee = EinsumPlanner(torch.device("cuda:0"), cuda_mem_limit=0.7)
其中 models_allowed=['Ising','Potts','XY','GXY']。
清单3:模型和结果
1 def SVD(t, left_indices, right_indices, D):
2 T = torch.permute(t, tuple(left_indices + right_indices)) if use_cuda else np.transpose(t, left_indices + right_indices)
Models and Results
在本节中,作者展示了使用 TorchTrg 得到的结果。首先,作者比较了在 CPU 和 CUDA 架构上运行广义 XY 模型的时间,该模型是标准模型的一种变形。然后,作者讨论了将 TRG 方法应用于经典伊辛模型的情况,并讨论了作者如何更快地收敛到所需的精度。在本节的最后一部分,作者讨论了 q = 3 的 q 态波茨模型,并准确确定了与链续相变相对应的临界温度。
GXY 模型是标准 XY 模型的一种自旋向列形变[24]。在外部场作用下,其哈密顿量如下:
[ H = − Δ 2 ∑ ⟨ i , j ⟩ cos ( θ i − θ j ) − ( 1 − Δ ) ∑ ⟨ i , j ⟩ cos ( 2 ( θ i − θ j ) ) − h 2 2 ∑ i cos θ i ] [ H = -\frac{\Delta}{2} \sum_{\langle i,j \rangle} \cos(\theta_i - \theta_j) - (1 - \Delta) \sum_{\langle i,j \rangle} \cos(2(\theta_i - \theta_j)) - \frac{h^2}{2} \sum_i \cos\theta_i ] [H=−2Δ⟨i,j⟩∑cos(θi−θj)−(1−Δ)⟨i,j⟩∑cos(2(θi−θj))−2h2i∑cosθi]
其中,作者遵循标准记法, ⟨ i , j ⟩ \langle i,j \rangle ⟨i,j⟩ 表示最近邻, θ i ∈ [ 0 , 2 π ) \theta_i \in [0, 2\pi) θi∈[0,2π)。该模型有两个明确的极限:当 Δ = 0 \Delta = 0 Δ=0 时对应于纯自旋向列相,而 Δ = 1 \Delta = 1 Δ=1 时对应于标准 XY 模型。作者将在另一篇作品中报告此模型的张量公式化进展[25]。
为了测试作者的 GPU 加速,作者专注于两个模型。一个具有离散对称性(伊辛模型),另一个具有连续全局对称性(GXY)。由于 GXY 模型中初始张量的指标取无限值,从粗粒化的第一步就需要适当的截断,而对于伊辛模型,则根据初始张量的大小,多次迭代可以精确进行。
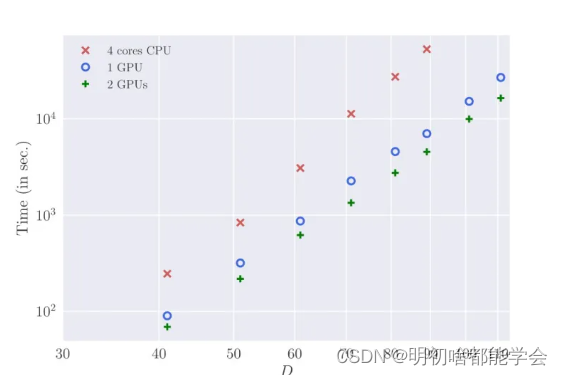
图2 显示了在大小为 230 x 230 的格点上,对于不同的 D,GXY 模型在 CPU 版本和 TorchTrg 中的运行时间(秒)的比较。作者使用 TorchTrg 中的最大 D = 111 和标准 CPU 版本中的 D = 89 进行比较。需要注意的是,这些时间仅仅是计算 Z,不包括任何不纯度量的计算时间。如果作者插入不纯度量(例如计算磁化),那么对于 D = 101,在单个 GPU 上的运行时间增加到大约 19,000 秒,而纯网络为 15,200 秒。
对于本文中的 GXY 模型,作者只考虑了 h = 0 的情况,并固定了参数值
Δ
=
0.5
\Delta = 0.5
Δ=0.5,对不同的 D 进行了张量计算。在 TorchTrg 中,这种模型的计算时间按照 ~ D^5.4(3) 的比例扩展,而在 CPU 上的计算时间接近 ~ D^7,这与二维高阶 TRG 扩展的预期一致。需要注意的是,SVD 计算的成本按照 ~ D^6 的比例扩展,而观察到的计算时间复杂度也表明,即使是 SVD 计算也通过 GPU 得到了加速,尽管相对于张量收缩而言它们是次要的。
作者在图2中展示了在 TorchTrg 中使用 CUDA 加速的效果的运行时间比较。作者使用了一块和两块配备 NVIDIA GeForce RTX 2080 Ti 的 CUDA 设备。作者发现使用两块设备的计算速度比单块快了大约1.5倍。此外,作者还测试了在四块配备 NVIDIA TITAN RTX1 的 CUDA 设备上的程序运行情况,相比于两块 CUDA RTX 2080 Ti,在一定的 D 上有进一步的加速,约为 ~1.3 倍(图中未显示)。因此,很明显,随着未来更好的 GPU 架构,TRG 计算将显著受益于完全转向基于 GPU 的计算。使用作者增强的 GPU 代码,可以访问更大的 D,并有可能准确计算临界指数。作者在方程 1 中固定
Δ
=
1
\Delta = 1
Δ=1 并计算了临界指数
δ
\delta
δ,定义为在
T
=
T
c
=
0.89290
T = T_c = 0.89290
T=Tc=0.89290 处的磁化
M
∼
h
1
/
8
M \sim h^{1/8}
M∼h1/8,得到
δ
=
15.11
(
17
)
\delta = 15.11(17)
δ=15.11(17),与精确结果 15 相比。结果在图3 中用 D = 111 显示。为了确保在关键维度上的收敛,作者还取了 D = 131,并发现两个 D 之间的磁化差异约为 ~
1
0
−
8
10^{-8}
10−8。
在图3中,作者展示了在临界温度下,在一个大小为236 x 230的格点上,XY 模型的磁化在有限磁场 h 下的情况。拟合结果为 0.877(3)。这表明了作者提出的算法对于具有已知解的模型也是有效的。
在前一小节中,作者比较了 GXY 模型的运行时间,但作者也希望测试具有已知解的模型上带有 opt_einsum 和 GPU 加速的算法。在这方面,作者考虑了在方格上的 Ising 模型,这使得它成为检验算法和收敛性质的良好候选者。作者将通过计算自由能来检查高阶 TRG 方法的准确性,自由能是 TRG 计算中可以访问的基本量。它可以直接从规范的正则配分函数 Z 在热力学极限下得到,即 F = − k T ln Z F = -kT \ln Z F=−kTlnZ。Ising 模型的自由能的精确结果由以下给出:
[ F = − 1 2 β ln ( 2 cosh ( 2 β ) ) − 1 2 sinh 2 ( 2 β ) cosh 2 ( 2 β ) ( 1 2 ln ( 1 + e − 8 β ) + ln ( 2 ) ) ] [ F = -\frac{1}{2\beta}\ln\left(2\cosh(2\beta)\right) - \frac{1}{2}\frac{\sinh^2(2\beta)}{\cosh^2(2\beta)}\left(\frac{1}{2}\ln\left(1 + e^{-8\beta}\right) + \ln(2)\right)] [F=−2β1ln(2cosh(2β))−21cosh2(2β)sinh2(2β)(21ln(1+e−8β)+ln(2))]
其中, β \beta β 是倒数温度,作者定义了 TRG 计算中自由能的误差为:
[ δ F F = ∣ F exact − F TRG ∣ ∣ F exact ∣ ] [ \frac{\delta F}{F} = \frac{|F_{\text{exact}} - F_{\text{TRG}}|}{|F_{\text{exact}}|}] [FδF=∣Fexact∣∣Fexact−FTRG∣]
作者展示了在各种温度下这个可观测量的结果,在图4的左面板中,以及在固定
T
=
T
c
T = T_c
T=Tc 时,针对各种
D
D
D (运行时间)的结果在图4的右面板中。图4左面板中的每个数据点在大约 2000 秒内使用了 4 个 Intel® Xeon® Gold 6148 核心。作者观察到的最大偏差(正如预期)在
T
=
T
c
≈
2.269
T = T_c \approx 2.269
T=Tc≈2.269 时,其中
∣
δ
F
F
∣
|\frac{\delta F}{F}|
∣FδF∣ 为
1.91
×
1
0
−
9
1.91 \times 10^{-9}
1.91×10−9。作者没有找到任何其他算法能够在相同的执行时间内达到这样的精度。需要注意的是,在进行此比较时,作者甚至没有使用 CUDA 加速。作者使用了 bond 维度
D
=
64
D = 64
D=64,在一个大小为
220
×
220
220 \times 220
220×220 的正方形格点上计算了自由能。为了确保结果已经适当收敛,作者还研究了
225
×
225
225 \times 225
225×225 的格点大小,并从精确结果中获得了相同的偏差。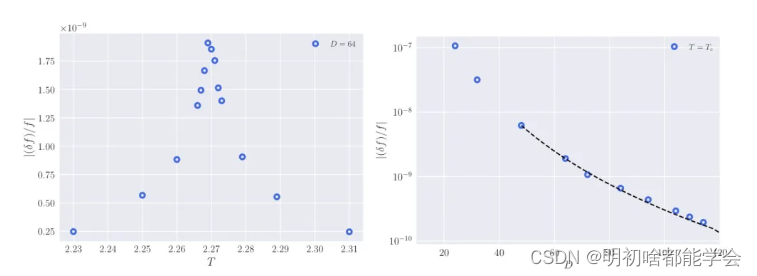
表1:在临界温度T= T时,针对220 x 220格点的伊辛模型的HOTRG算法的CPU和GPU时
间(以秒为单位)。
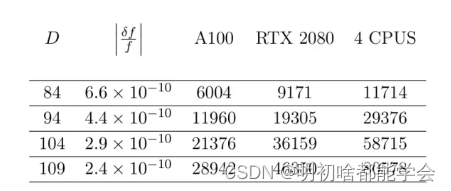
另一个有用的计算是系数
a
a
a,定义为
∣
8
δ
F
F
∣
×
1
D
|\frac{8\delta F}{F}| \times \frac{1}{D}
∣F8δF∣×D1。桐的 TRG 算法有不同的
a
a
a,较高的值表示随着边界维度
D
D
D 的增加收敛更快。作者在图4的右面板中展示了在
T
=
T
c
T = T_c
T=Tc 时,伊辛模型中误差随
D
D
D 的变化。对
D
∈
[
48
,
114
]
D \in [48, 114]
D∈[48,114] 的数据进行数值拟合,得到的拟合结果是
a
=
4.12
(
2
)
a = 4.12(2)
a=4.12(2)。这个指数与临界
c
=
1
/
2
c = 1/2
c=1/2 的伊辞模型的纠缠熵的标度有密切关系,后与
ξ
∼
D
1
/
ν
\xi \sim D^{1/\nu}
ξ∼D1/ν 给出的有限
D
D
D 相关长度的标度有关。人认为,在
d
=
2
d = 2
d=2 维伊辛模型中,自能的误差标度像
ξ
d
\xi^d
ξd,在
T
=
T
c
T = T_c
T=Tc 时误差最大,此时相关长度发散。这意味着
∣
8
δ
F
F
∣
×
D
−
2
∝
k
|\frac{8\delta F}{F}| \times D^{-2} \propto k
∣F8δF∣×D−2∝k。利用这个关系,作者得到
k
∼
2.06
k \sim 2.06
k∼2.06,这与预期的指数
k
∼
2.03425
k \sim 2.03425
k∼2.03425 非常接近。
对于这个模型,作者还与另外两篇近期的工作进行了比较。在引入的三元-次重整化群方法中,只能以大约 10 秒的 CPU 时间在 T = T c T = T_c T=Tc 达到 1 0 − 9 10^{-9} 10−9 的精度,这大致相当于作者的 CPU 代码在获得相同精度的伊辛模型时快了大约 30 倍。尽管在远离临界温度时表现得更好,但在临界温度下即使 D = 64 , 128 D = 64, 128 D=64,128 也没有 1 0 − 9 10^{-9} 10−9 的精度。作者比较了伊辛模型的 CPU 和 GPU 代码,结果总结在表1中。作者发现使用 NVIDIA A100 的性能要比 RTX 2080 好得多。